Data Driven Allocation: A Deep Dive
Intro
When planning marketing budgets, it can quickly get complicated, juggling between different tactics, KPIs, and different groups of people with different perspectives can quickly make the process more challenging.
By integrating a MMM, forecasts can be generated, which will allow stakeholders to see and easily understand the impact on the business that the marketing budget shifts will have, helping to shift the conversation into one with concrete goals and business understanding from a holistic perspective.
The Robyn MMM is an advanced open source MMM from Meta Science Lab, an open source cutting edge Marketing Mix Model, that we can use to generate forecasts to plan out marketing budgets.
Data Preprocessing
Lets hop into R and import the sales data to get started, it has sales data along with TikTok, Facebook, and Google Ads spend broken out by week. We'll also need to do some light preprocessing to feed it into Robyn.
data <- read_csv("marketing_mix.csv")
#format the date column into the format Robyn needs
data$Date <- mdy(data$Date)
#pull in the list of holidays that is the default for the Robyn package, that includes major US holidays
holidays <- dt_prophet_holidays
Generating the models with Robyn
Robyn uses 'Input Collect' to contain the inputs that will be used to build the models. Lets prefill it here, to make our code more readable.
InputCollect <- robyn_inputs(
date_var = 'Date',
dep_var = 'Sales',
dt_input = data,
dt_holidays = holidays,
paid_media_spends = c('TikTok', 'Facebook', 'Google_Ads'),
paid_media_vars = c('TikTok', 'Facebook', 'Google_Ads'),
prophet_country = 'US',
window_start = '2018-1-7',
window_end = '2021-10-31',
adstock = 'geometric', #can also be weibull_cdf or weibull_pdf, but for #later parts in this example to work, this must be geometric.
dep_var_type = 'conversion' #can also be 'revenue'
)
Now that everything is prepped, lets generate the models
OutputModels <- robyn_run(InputCollect = InputCollect,
cores = NULL, #if left null cores, will default to the max available - 1
iterations = 2000,
trials = 5,
ts_validation = TRUE,
add_penalty_factor = FALSE)
Now that we have the models, we can use OutputCollect to generate some one-pagers(documents that give an overview of the model's performance) and allocations straight from Robyn, but most important for right now, it can also cluster similar models together, trimming the amount of models that we need to go through.
OutputCollect <- robyn_outputs( InputCollect, OutputModels, pareto_fronts = "auto", # automatically pick how many pareto-fronts to fill min_candidates (100) min_candidates = 100, # top pareto models for clustering. Default to 100 calibration_constraint = 0.1, # range c(0.01, 0.1) & default at 0.1 csv_out = "pareto", # "pareto", "all", or NULL (for none) clusters = TRUE, # Set to TRUE to cluster similar models by ROAS. See ?robyn_clusters export = create_files, # this will create files locally plot_folder = robyn_directory, # path for plots exports and files creation plot_pareto = create_files # Set to FALSE to deactivate plotting and saving model one-pagers)
Robyn has a feature that allows for previously generated models to be reloaded for later use, called ‘refresh’. However I prefer to simply save the .rds objects themselves, as I have found it to be a more intuitive and consistent process. Also, if the OutputModels object is saved, all the models can be saved, in case the clustering doesn’t include a model that would be later used.
saveRDS(OutputModels, file = "output_models.rds")
loaded_data <- readRDS("output_models.rds")
saveRDS(OutputCollect, file = "output_collect.rds")
OutputCollect <- readRDS("output_collect.rds")
Response Curves
We can generate a response curve via the 'robyn_response' function.
tiktok_curve <- robyn_response( InputCollect = InputCollect, OutputCollect = OutputCollect, select_model = select_model, metric_name = 'TikTok', metric_value = 2000, date_range = "last_5" # can also be a range, ie: c('2018-01-14', '2018-02-04') )
This scales the curve to fit the data from the selected range, meaning that we can get a scaled curve to account for different seasonalities that the business has experienced in the past. I'm keeping it simple and using the last 5 periods in this case, but using the data from the previous year would allow for the scaling to account for the seasonality of the upcoming period.
However, this doesn’t give us what we need, it's not a continuous curve, we instead get a distinct selection of points, which isn’t going to help generate the flexibility in predictions that we need to make a dynamic dashboard.
So let’s generate the saturation curve.
#get the alpha and gamma from the model, it's in the OutputCollect$resultHypParam, just find the ones that match the model and tactic.
alpha <- subset(OutputCollect$resultHypParam$TikTok_alphas, OutputCollect$resultHypParam$solID == '5_86_3')
gamma <- subset(OutputCollect$resultHypParam$TikTok_gammas, OutputCollect$resultHypParam$solID == '5_86_3')
#generate a vector of numbers between 0-1, we’ll need this to feed into the saturation formula
x <- seq(0, 1, length.out = 500)
#make a copy of that vector
y <- numeric(length(x))
#feed the sequence into the equation for the saturation curve for the geometric models.
for (i in 1:length(x)) {
x1 <- x[i]
y[i] <- (x1^alpha) / (x1^alpha + gamma^alpha)
}
#scales the curve
tactic_spend <- tiktok_curve$plot$data$metric
tactic_response <- tiktok_curve$plot$data$response
expected_spend <- x * max(tactic_spend)
response <- y * max(tactic_response)
response <- response * (max(tactic_response) / max(response))
This results in the curve that Robyn gave us, but now we can access the full curve and generate sales for any amount of spend that we like.
We can take this equation and put it transfer it into other programs, such as Tableau in a calculated field:
round((((([Budget Parameter] / max(tactic_spend)^alpha) / (([Budget Parameter] / max(tactic_spend)^alpha + gamma^alpha)) * max_tactic_response) * (max(tactic_response) / max(response))
We can take the constants from the values that we have already calculated in R, to fill in the equation, and use [Budget Parameter] to feed in spend values that the user selects.
There is one thing to consider however: the curve we have made is finite, what if budgets are to increase beyond the curve's limits?
Well given how the saturation curve is generated here, we can’t use Robyn directly to achieve this, as the underlying equation has a hard limit on the values it can generate.
We can however estimate what it would be with machine learning. However this comes with it's own drawbacks that I’ll get into.
Machine Learning Extension
To start, let's fit the data into the machine learning model, for this example, I’m going with a simple linear regression.
plot_data <- data.frame(expected_spend, response)
model <- lm(response ~ poly(x, degree = 18), data = plot_data
Note that I’m not splitting the data into training or testing sets, and that I am using a really high degree for this prediction.
That’s because we want it to fit the response curve as best as we can,
remember we aren’t predicting the sales right now, we’re predicting the prediction that Robyn would give of the sales, so any distortion will be magnified.
Now that we have this, it's harder to export, simply writing the equation is a much more involved process this time around. Tableau also has limitations on
importing machine learning models, requiring an Rserve to be running to process it. Instead for this example, I’ll use an Shiny app in an RMarkdown file.
Lets go ahead and save the .rds of the model so we can easily import it into the RMarkdown going forward:
saveRDS(model, file='model.rds')
Let's quickly set up the Shiny App.
ui <- fluidPage(
titlePanel(‘MMM Curves’),
sidebarLayout(
sidebarPanel(
sliderInput('tactic_budget',’tactic_budget', value=1500, min=1, max=[max], ticks=FALSE),
textOutput(outputId = 'tactic_sales'),
textOutput(outputId = 'tactic_cost_per_sale'),
mainPanel(
fluidRow(
column(6, plotOutput(outputId = 'tactic_plot')),
))
server <- function(input, output) {
output$tactic_budget <- renderPlot({
Spend <- seq(0, input$tactic_budget, length.out=input$tactic_budget)
Sales <- predict(google_model, newdata = data.frame(Spend))
ggplot(data = data.frame(Spend, Sales), aes(Spend, Sales)) +
geom_line() +
labs(title = "Google Sales Curve")
})
output$tactic_sales <- renderText({
x <- seq(0, input$tiktok_budget, length.out=input$tiktok_budget)
y <- predict(model, newdata = data.frame(Spend = x))
paste('Sales:', round(max(y)))
})
output$tactic_cost_per_sale <- renderText({
x <- seq(0, input$google_budget, length.out=input$google_budget)
y <- predict(google_model, newdata = data.frame(metric = x))
z <- max(x) / max(y)
z <- (round(z * 100)) / 100
paste('Cost per Sale:', z)
}))
shinyApp(ui, server)
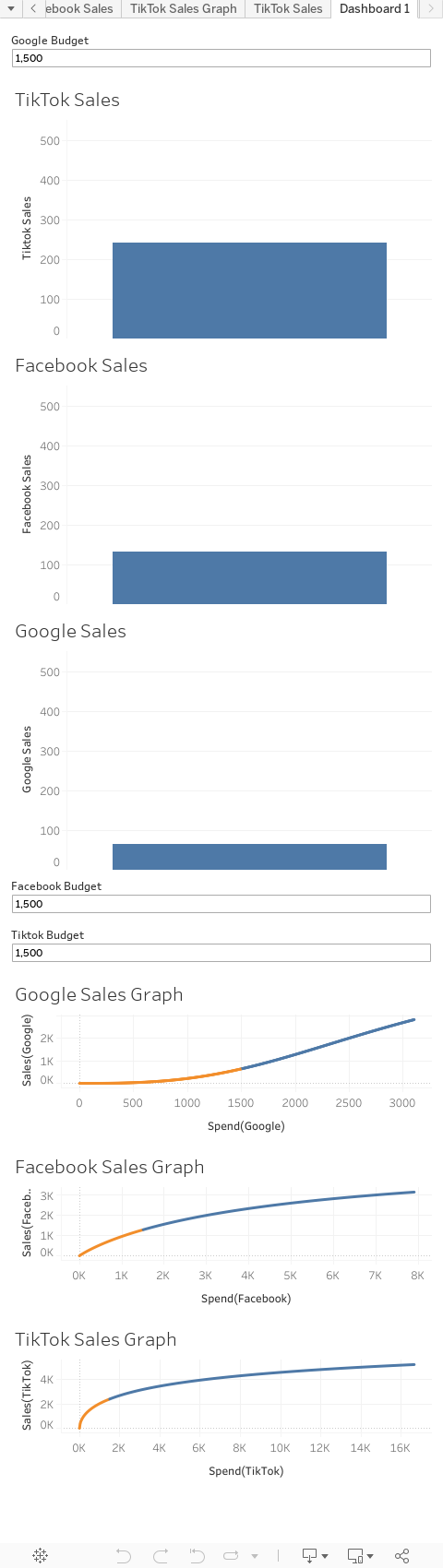
If we apply that boilerplate code to all three tactics, we get this:

Now while we have increased the range that the user can input, you will notice that there are still limits. That is because since we overfit the model on purpose as detailed earlier, the model misbehaves if we extend too far past the previous limits.

This goes to illustrate that in order for this to be used, stakeholders need to be informed of the limitations of these forecasts, and have their expectations set accordingly. If that is achieved this can be an extraordinary tool in planning budgets, that is extremely flexible. It can be used more granularly, on individual campaigns within tactics to have more detailed forecasts, and in addition, as long as there is data over time corresponding with marketing spend, any KPI could be forecasted, such as website sessions or newsletter signups in addition to revenue or sales it was designed for.
Resources Used
Meta's Robyn MMM open source R package, Kaggle user Veerendra's sample data.

